Residential Proxies for Web Scraping
Clean ISP residential IPs that prevent blocks, avoid CAPTCHA, and provide reliable scraping performance on any site.
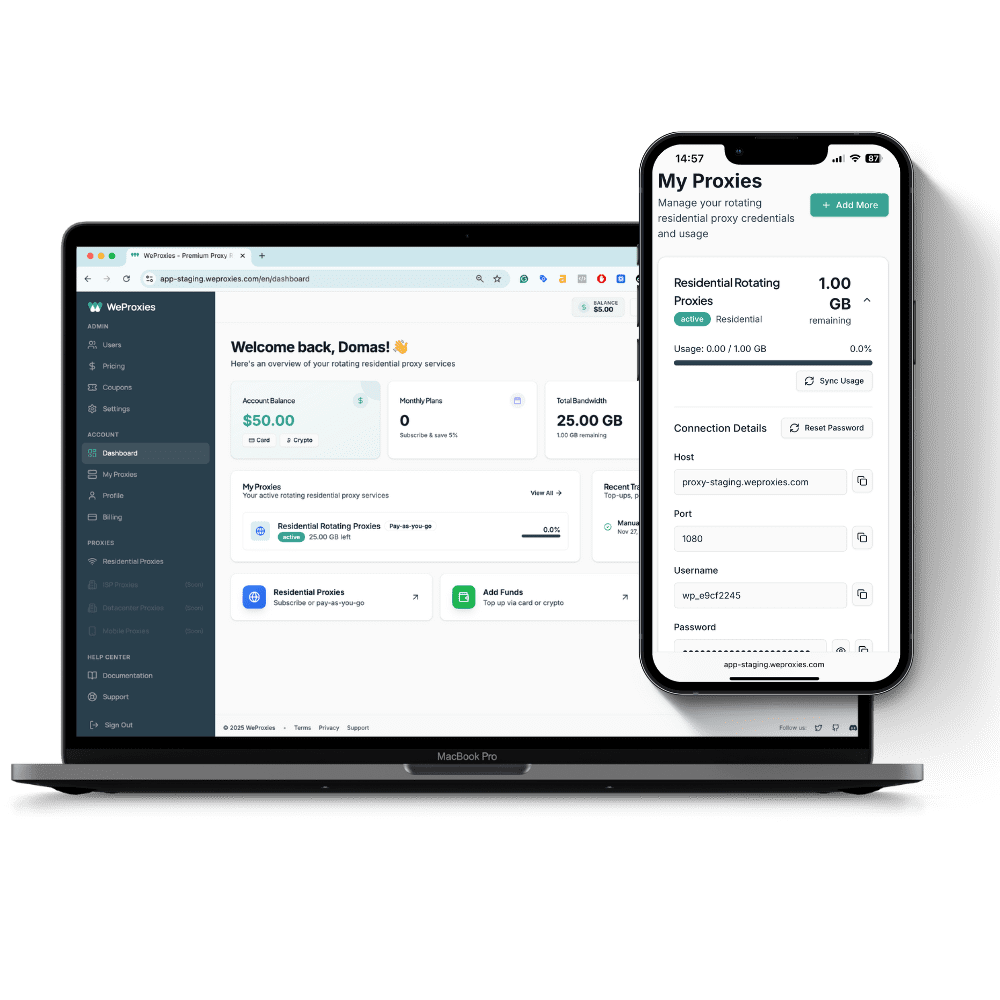
Seamless integrations:











What Are Scraping Proxies?
Web scraping proxies give you the ability to browse websites without the risk of getting your requests limited, blocked, or detected by anti-bot systems. By using actual ISP residential IPs, your requests blend in with normal user traffic, thereby increasing the chances of success on various platforms such as search engines, e-commerce sites, travel sites, review sites, etc.

Why WeProxies is Perfect for Web Scraping
✔ Real ISP Residential IPs
Clean, trusted IPs that deliver higher success rates and fewer CAPTCHAs.
✔ Automatic Rotation
Fresh IP on every request, ideal for high-volume scraping.
✔ Sticky Sessions Available
Keep the same IP for minutes or hours when your scraper needs session stability.
✔ Global GEO Targeting
Choose IPs from the US, EU, and Asia for accurate, localized scraping.
✔ Unlimited Threads
Scale your scraping jobs without restrictions or throttling.
✔ Simple Integration
Compatible with Python, Node.js, Selenium, Puppeteer, Playwright, Scrapy, and more.
Ideal for Any Scraping Workflow
🛒 E-commerce Scraping
Amazon, Walmart, Shopify, price monitoring, product data.
📈 SERP Scraping
Google search results, keyword tracking, SEO data.
📝 Review & Listings
Yelp, TrustPilot, TripAdvisor, booking sites.
📊 Market Intelligence
Competitor research, trend monitoring, analytics.
📰 News & Content
Article extraction, content aggregation, sentiment analysis.
🌍 GEO-Restricted Content
Access region-specific results and localized content.
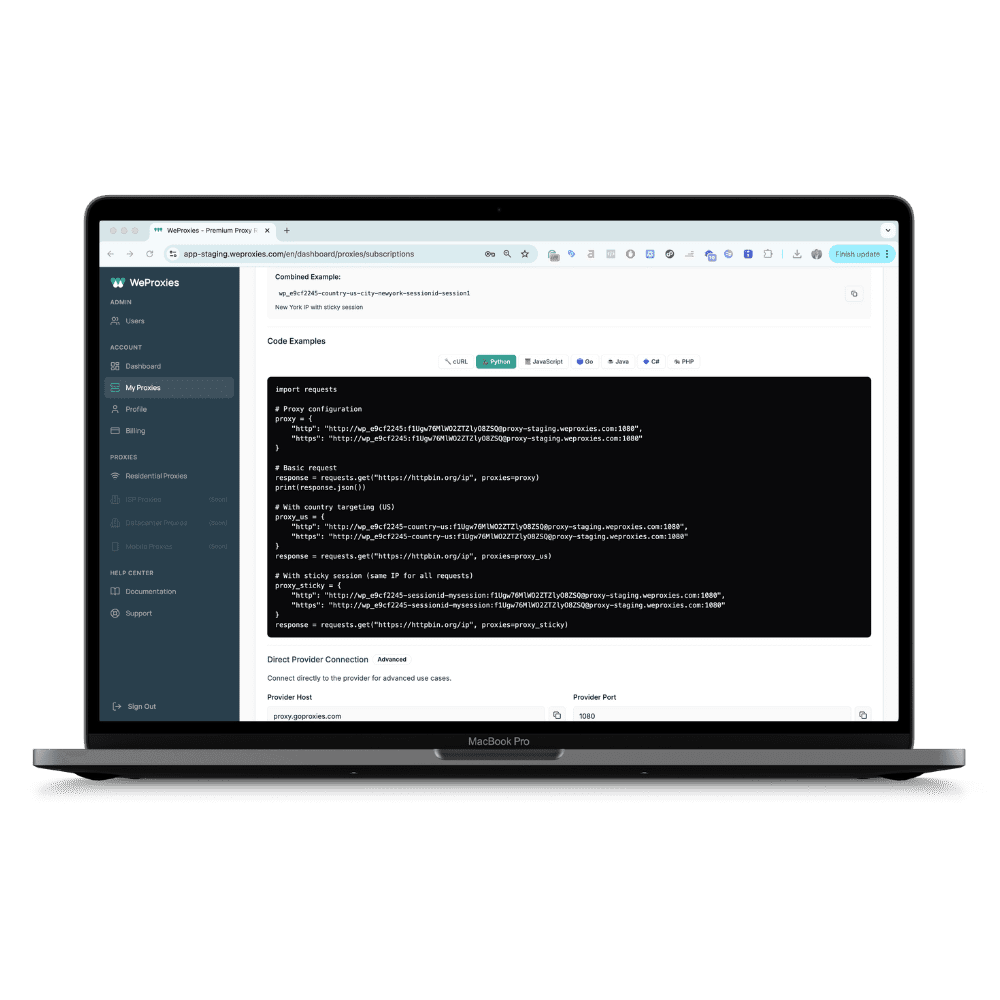
import requests
# Proxy configuration
proxy = {
"http": "http://wp_e9cf2245:f1Ugw76MlWO2ZTZlyO8ZSQ@proxy-staging.weproxies.com:1080",
"https": "http://wp_e9cf2245:f1Ugw76MlWO2ZTZlyO8ZSQ@proxy-staging.weproxies.com:1080"
}
# Basic request
response = requests.get("https://httpbin.org/ip", proxies=proxy)
print(response.json())
# With country targeting (US)
proxy_us = {
"http": "http://wp_e9cf2245-country-us:f1Ugw76MlWO2ZTZlyO8ZSQ@proxy-staging.weproxies.com:1080",
"https": "http://wp_e9cf2245-country-us:f1Ugw76MlWO2ZTZlyO8ZSQ@proxy-staging.weproxies.com:1080"
}
response = requests.get("https://httpbin.org/ip", proxies=proxy_us)
# With sticky session (same IP for all requests)
proxy_sticky = {
"http": "http://wp_e9cf2245-sessionid-mysession:f1Ugw76MlWO2ZTZlyO8ZSQ@proxy-staging.weproxies.com:1080",
"https": "http://wp_e9cf2245-sessionid-mysession:f1Ugw76MlWO2ZTZlyO8ZSQ@proxy-staging.weproxies.com:1080"
}
response = requests.get("https://httpbin.org/ip", proxies=proxy_sticky)
How Web Scraping With WeProxies Works
- Connect Your Scraper – Use our endpoint with your tool (Python, Node, Postman, etc.).
- Choose Rotation Settings – Select rotating or sticky sessions.
- Start Collecting Data – Scrape without blocks, CAPTCHAs, or IP bans.
import requests
# Proxy configuration
proxy = {
"http": "http://wp_e9cf2245:f1Ugw76MlWO2ZTZlyO8ZSQ@proxy-staging.weproxies.com:1080",
"https": "http://wp_e9cf2245:f1Ugw76MlWO2ZTZlyO8ZSQ@proxy-staging.weproxies.com:1080"
}
# Basic request
response = requests.get("https://httpbin.org/ip", proxies=proxy)
print(response.json())
# With country targeting (US)
proxy_us = {
"http": "http://wp_e9cf2245-country-us:f1Ugw76MlWO2ZTZlyO8ZSQ@proxy-staging.weproxies.com:1080",
"https": "http://wp_e9cf2245-country-us:f1Ugw76MlWO2ZTZlyO8ZSQ@proxy-staging.weproxies.com:1080"
}
response = requests.get("https://httpbin.org/ip", proxies=proxy_us)
# With sticky session (same IP for all requests)
proxy_sticky = {
"http": "http://wp_e9cf2245-sessionid-mysession:f1Ugw76MlWO2ZTZlyO8ZSQ@proxy-staging.weproxies.com:1080",
"https": "http://wp_e9cf2245-sessionid-mysession:f1Ugw76MlWO2ZTZlyO8ZSQ@proxy-staging.weproxies.com:1080"
}
response = requests.get("https://httpbin.org/ip", proxies=proxy_sticky)
Residential vs Datacenter Proxies for Scraping
| Feature | Residential | Datacenter |
|---|---|---|
| Best for strict sites | ✔ | ✖ |
| Captcha avoidance | ✔ | ✖ |
| Success rate | High | Medium |
| Speed | Medium-High | High |
| Risk of ban | Low | Medium-High |
| Ideal use | E-com, SERP, travel | Bulk tasks, low-security sites |
Get Scraping Proxies for the Best Price
Need Enterprise-Scale Proxies? Contact Us for Enterprise Plans.
Scraping Proxy FAQs
Are residential proxies good for scraping?
They are indeed the best. Scraping employing residential proxies is the most powerful choice because they are rerouting your traffic through the real IPs given by ISP. Your requests, which seem to be normal user activity, are, thus, helping you to get rid of blocks, CAPTCHAs, and limits in the case of strict websites like e-commerce, search engines, travel sites, and review platforms, etc.
Is it possible to rotate IPs automatically?
Yes, indeed! WeProxies has an automatic IP rotation support so you can have a different residential IP for every request or after a custom interval. Also, you can always opt for sticky sessions when the same IP needs to be active for longer tasks like logged-in scraping or checkout flows.
Which websites are you allowed to scrape?
You can scrape any website that is open to the public, ranging from e-commerce sites to search engines, social networks, travel sites, marketplaces, review sites, and so on. Moreover, our residential IPs are specially designed to function on those strict websites that often prohibit the use of datacenter proxies.
How many requests per second are allowed?
The number of concurrent requests that you can make is up to your bandwidth and the capacity of your infrastructure. There are no limitations on WeProxies threads or simultaneous connections. In fact, our residential proxy network is built for high-volume scraping workflows which is why it performs so well even at the scale of operations.
What locations do you support?
We are offering residential IPs in key areas such as the United States, Europe, Asia, and other parts of the world. With the option of GEO-targeting, you can choose certain countries, and sometimes even cities, to acquire the precise, localized data for your scraping processes.
Do you block any scraping tools?
No way. WeProxies is compatible with all the most widely-used scraping tools and libraries including Python Requests, Selenium, Puppeteer, Playwright, Scrapy, Postman, and Node.js. We won’t block any legitimate scraping processes, automation frameworks, or API clients. You can use any tool that supports HTTP or SOCKS5 proxies without any restrictions.